Disclaimer: All images and ads in this post are for spec commercial examples only. The originator of the
commercial is not affiliated with, connected to, nor sponsored or endorsed
by Clash of Clans (or Starbucks).
TLDR: Fully formed art, but difficult to control details
AI Text to image models have seen explosive growth the past year matched with an equally explosive growth of an assumption that AI generated images will replace graphic design and artist roles. I am not a graphic designer but in my role of developing advertising automation solutions for mobile games, the creative development process is something I’ve worked near for years.

In short the AI image creation goes from nothing to fully formed image with no effort, but specific inputs or requirements increase the difficulty immensely. AI image generation is the perfect tool for creating a never before seen magical world, but if your requirements are more specific than that, it can feel quite difficult to impart your intentions into the chaos of the random image generation.
For example, this generated photo of a Starbucks coffee mug logo is OK, but the mermaid logo’s face is slightly odd. Further steps can get it closer to the original logo, but ultimately it never will be the exact right logo or the exact right color green, because those requirements ultimately comes from the brand creator and cannot be randomly generated by the AI and would instead later need to be added.
The setup and tools: Stable Diffusion
For our imaginary use cases we will use Clash of Clans as our example spec advertisement. Clash of Clans is a popular mobile game with a proliferation of content, so the image databases used to train the models already have a fair amount of tagged image content. Stable Diffusion is built on models based on 5B images, scraped from the internet, and fully searchable on LAION-5B: Searchable Database of 5B Tagged Images. Stable Diffusion starts from a random noise pattern (like static on a TV) then iterates until patterns begin to form that match your text or image input.
I ran all these images through the Web UI provided by AUTOMATIC1111, this UI allows you to run edit and play with Stable Diffusion in your own browser. The images were run on a regular laptop with 4GB GPU memory, so all images were output with the bare minimum settings. Of course, if you have the recommended 12GB GPU memory your outputs should look much better. In general I found that the iterative approach worked best, so was able to break the project into smaller steps which usually fit nicely into my 4GB memory.
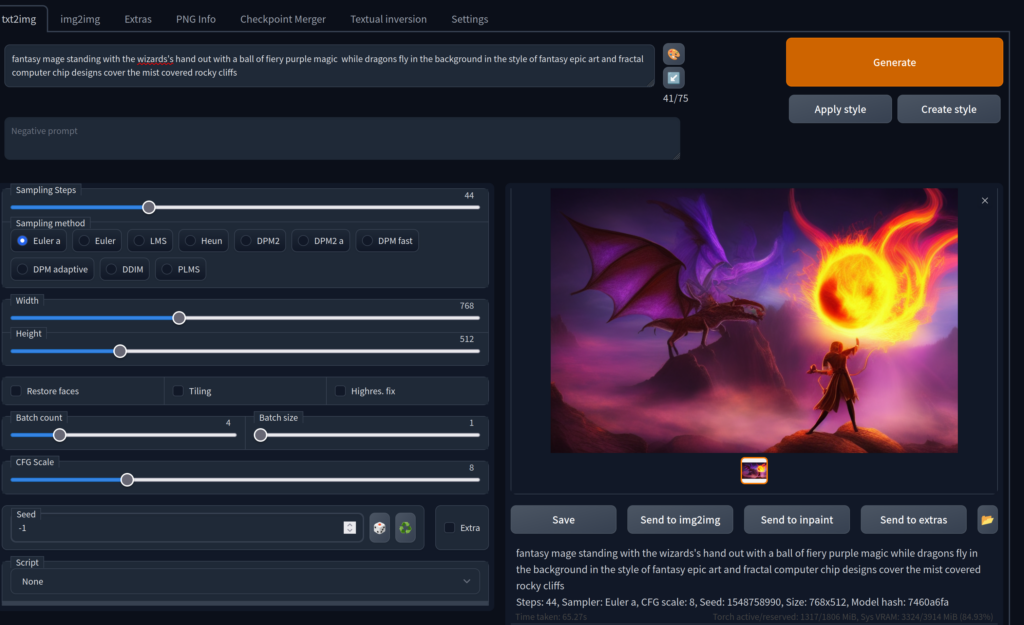
Use Case 1: Resizing an Ad from Landscape to Portrait
A common situation marketers encounter is after a set of creatives are created, at some point in the future they may encounter an advertising platform with different dimension requirements.
To start the following creative is 1140×700 pixels but we need to transform it to 900×1600 pixels. This is quite difficult as you not only need to resize the image, but also fill in the additional empty space. Stretching the image would distort the creative to the point of being unusable, putting in blurry backgrounds is another simple fix, but still an aesthetically lacking option.
First Try: Img2Img
Using Img2Img with a prefilled image will set a tone for the image to be generated. I tried several rounds of pure Img2Img, and while some basic contents were similar (note the characters on left, white light background on right) the content was so wholly different that it invalidated the original use case to use the original art. I want to keep as much of the original art as possible, so this doesn’t cut it.



Step in the right direction: InPaint
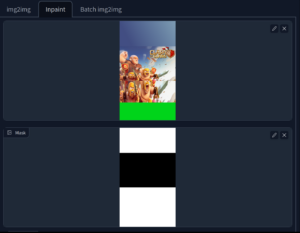

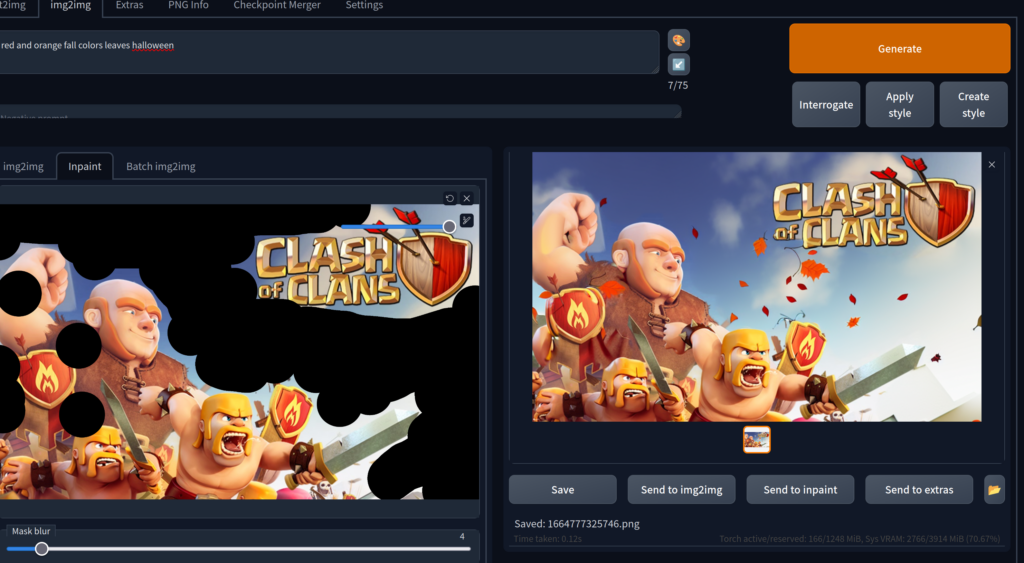
In our next attempt, we use InPaint which has the tool for creating a mask (the white and black part), which select which parts of the image should remain original and which should be generated. In this case, the white and black below correspond to the generated and untouched parts of the image respectively. The remaining image (blue sky / some of the original image and green for grass) are then used for Img2Img inputs.
This gets us much closer to something that looks OK. We have a purple character above and a semi-convincing charge of men below. The line between the images does not blur very well and the their body positions are illogical. The entire scene at the very bottom is the worse as the men closer to monsters than Clash of Clans characters.
Keep the image: Fix the remaining issues
We can try to fix these by further rounds of InPainting, focusing on specific sections. For example, let’s remove the purple sky man in favor of clouds.
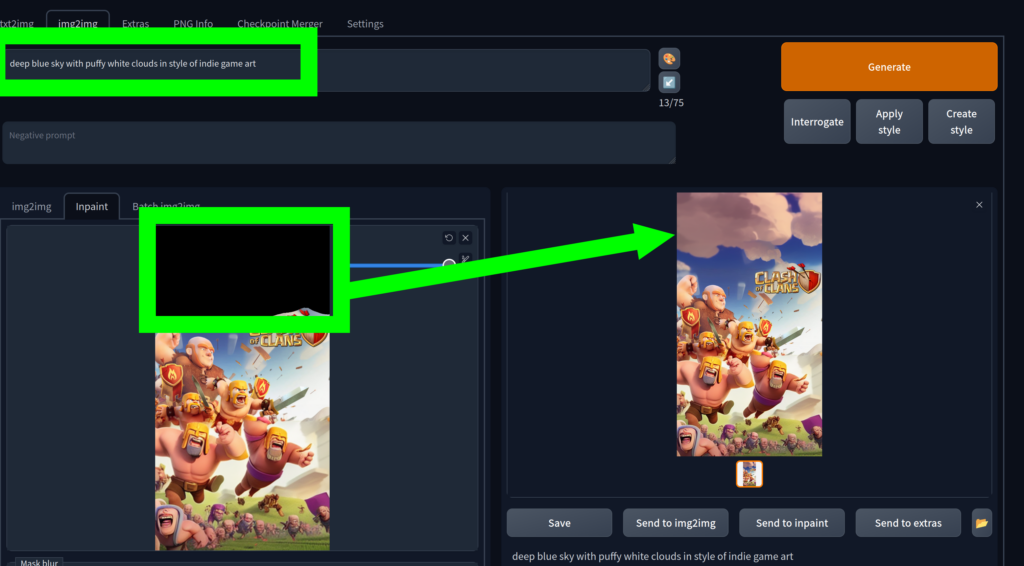
Trying to get the faces to be more “on brand”
The two faces in the bottom of the image were still bothering me as they didn’t quite look like the Barbarian character from Clash of Clans. The main issues were the lack/odd eyes and non yellow beards. What initially felt like a quick fix turned into a much longer process of trial and error, generating dozens of attempts.
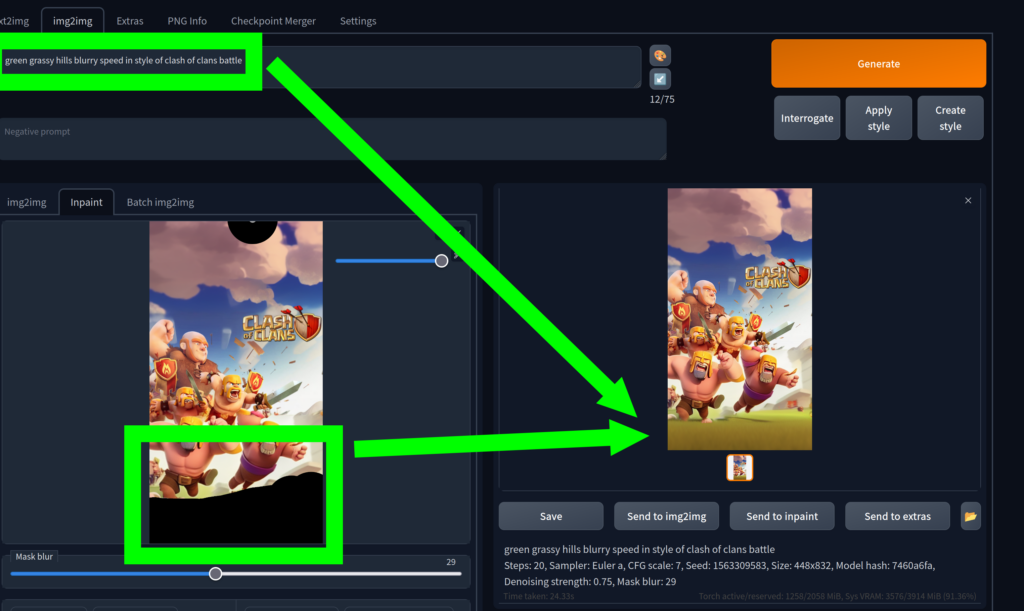

Finally, I tried searching through LAION-5B database, which was used to train the Stable Diffusion model. I found that probably the best input for getting two good Clash of Clan’s barbarian faces was to simplify my input to “clash of clans icon yellow”. In the search on LAION-5B database this returned the highest density of typical Clash barbarian characters.
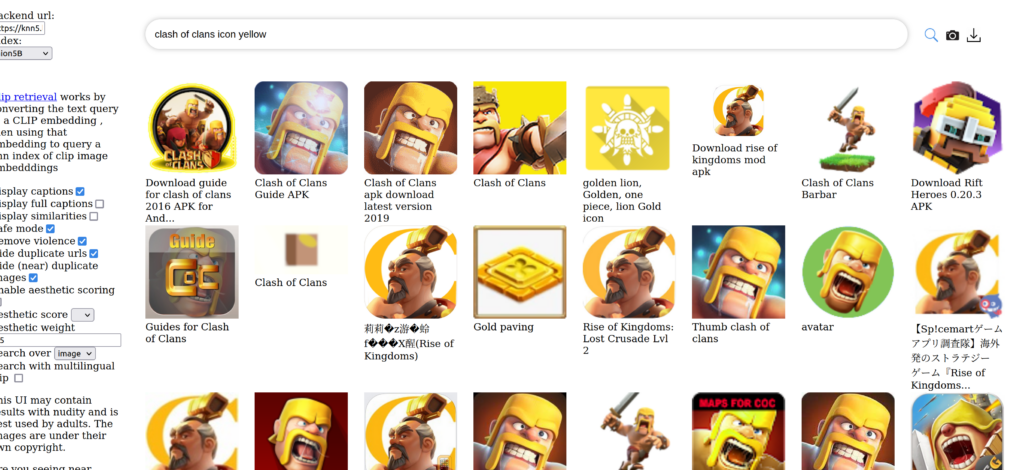
Use Case 1: Final Resized Image
After getting the last two faces’ beards fully yellow, I had arrived at what my dwindling patience told me is the final product. The outcome is something only a parent can be proud of, and while interesting, would not be something that any branded advertisers would be comfortable using as an advertising creative.
The difficult in controlling the coloring and themes leads to character faces are very similar to Clash of Clans branding, but ultimately not on brand.
A higher order issue is that while we did solve our initial problem to resize the original image, we did not do it in a way that is flexible for future changes. The end product is a fully rasterized image, which means that it is even less flexible were it needed to be further resized for another set of dimensions. A typical work file from a creative team would include each section or character in their own folders and layers, allowing for quick modifications later.
A time breakdown of generating this image was as follows:
- Setup: 0.5hr
- First images to the clouds: 1hr
- Generating the two faces: 1.5hr
Overall generating this use case felt like it became a slower and slower process as I tried to exert a high level of control over the image being output.
Use Case 2: Themes
Sometimes for holidays you may want to modify existing creatives to add a holiday theme. This is usually a pretty simple process for creative teams, but for smaller companies there might not be enough time or manpower to dedicate for creating a steady stream of themed content. Let’s see how well we can take our original creative and add a Halloween theme.
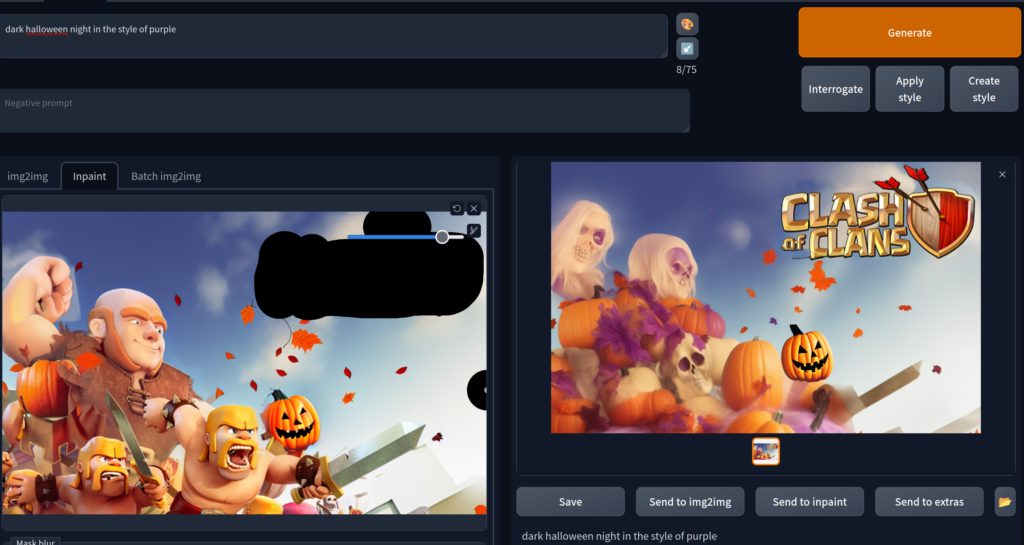
Let’s start with some fall colors and see what we get.
And now let’s add some pumpkins!

Losing the plot, trying to get more of the Halloween theme
Trying to take the Halloween theme further it is really easy to quickly get off track. The image below is just an example, but most images quickly become 100% unrelated to the original image. Again this underscores the true power of Stable Diffusion: that it can so quickly generate incredibly unique and interesting images, but attempting to exert precision over them is difficult.

Use Case 2: Final Product
Trying to prevent Stable Diffusion from generating it’s own images is a bit tiring, so let’s just add more pumpkins and call this done. The final product got a little bit of a fall vibe to it, but let’s be honest, not much. I didn’t document it, but I went on a long tangent attempting to turn the background sky dark / night time, but without any success. I found it difficult to truly give this a good fall motif without losing the original art. Again, this was 2+ hours of experimentation for what in the end felt a bit like bad clip-art. This use case didn’t feel anywhere near as good as the first one, though it did seem promising at first.

Case Study 3: Learn from our mistakes, try again
If Stable Diffusion is so good at generating completely new images, perhaps we shouldn’t try to start with a base creative, however let’s see what we can generate completely new? Let’s retry the two original case studies but from that angle.
Case Study 1: Input “clash of clans advertisement crowd of charging guys running towards a clash of clans giant” total time ~10 minutes, minimal tweaking settings
What a huge change, allowing the Text to Image to manage itself allows for some very unique and interesting scenes, and allows me to do a bit more “gambling” simply allowing the random generation of images to do the heavy lifting to find a good image.
Getting back to our themes, lets make a few themed images. Here’s two groups of four images for both Halloween and Christmas. It was so quick, these took a few minutes each and I didn’t even play with settings to fix anything up on them.


In total I spent mere minutes crafting the above sets of images, a fraction of the time as others, and arguably better looking scenes came out of it. To me, it felt like the less precise control I tried to exert, the better the results.
Final Thoughts & What’s Next for Marketers
Image generation needs more modular components for artists and marketers alike to manipulate. For example, outputting backgrounds, characters and objects as separate images and then composing them. This would allow flexibility later when working with the image. The landscape of image generation has been changing quickly and more and more the tools built around Stable Diffusion. I foresee further chaining together multiple AI algorithms and editing tools to enable more diverse use cases. I think what may come out of these are new specialized roles for artists who can create images from these tool sets.
Marketers meanwhile will find new uses for newly created images that are not quite on brand. Think rapid concept art prototyping and much wider ranges of A/B testing. Think social media marketers able to respond to simple messages with witty replies that contain unique images tailored to that day’s news or memes.
I see Stable Diffusion as a boon, the clip-art of our generation bringing art closer to everyone and the tools for marketers to create better experience ads.
If you have any questions, feel free to contact me or reach out .